
If you’ve spent any time on LinkedIn or tech Twitter lately, you’ve probably seen the hot takes: AI will replace most knowledge workers within a year. Software engineers are already obsolete, they just don’t know it yet. Your job is on borrowed time.
Take a breath. The timeline those predictions depend on has a massive assumption baked into it: that AI will keep getting dramatically cheaper, fast enough to make human labor uneconomical across the board. The technology side of that equation might hold up. The economics side almost certainly won’t.
That’s actually good news.
The tech is real. The timeline isn’t.#
To be fair, the trend is real. LLMs have gotten more capable while inference costs have dropped. Smaller models are doing work that required massive models a year ago. If you draw a line through those data points and extend it forward, you get a world where AI is so cheap that hiring a human to do the same work stops making financial sense.
I get the logic, but it’s only looking at the technology. The economics tell a different story. That trend line exists in a world where the infrastructure required to deliver AI at scale has hard physical constraints, and those constraints push costs in the opposite direction.
Hard costs don’t follow software curves#
Even if AI demand stayed perfectly flat from today (it won’t), we’d still need to build significantly more data centers. The current infrastructure can’t handle existing workloads at the scale companies want to run them.
Building a data center takes, what, two to four years from site selection to operational? And that’s if permitting goes smoothly, supply chains hold, you can actually secure the power allocation from your local utility, and you’ve greased the right local politicians to fast-track things a bit. You’re not deploying code. You’re pouring concrete, running power lines, and negotiating water rights.
And securing that power isn’t a formality. It’s becoming the primary bottleneck. Dominion Energy in Virginia, the largest data center market in the world, has warned that data center power demand could threaten grid reliability and has a multi-year interconnection queue. Georgia Power paused new large load connections entirely, including data centers, because their grid couldn’t absorb the demand. These aren’t hypothetical concerns. These are utilities telling billion-dollar companies “we literally cannot give you the electricity you need right now.”
Each large AI data center consumes as much power as a small city. The IEA projects global data center electricity consumption could double by 2026, exceeding 1,000 TWh. Some providers are exploring nuclear power, not because it’s trendy, but because nothing else generates enough baseline capacity to keep up.
Then there’s water. AI inference generates heat. Cooling that heat requires water, and lots of it. Google’s 2024 environmental report showed a 17% year-over-year increase in water consumption, largely attributed to AI workloads. Data centers in arid regions are already competing with agriculture and residential use for water access.
GPU prices have skyrocketed due to demand. High-bandwidth memory, networking equipment, specialized cooling systems, even the skilled labor to build and run these facilities. All of it is in higher demand than the supply chain can comfortably handle. When your input costs rise across the board, your output prices rise too. That’s not a market failure. That’s how markets work.
None of these costs disappear because the models get more efficient. You still need the building. You still need the power. You still need the cooling. These are hard costs with hard timelines, and they don’t care about your software release cycle.
This market isn’t what you think it is#
Here’s something most people don’t factor in: the AI token prices you see today are almost certainly subsidized.
OpenAI shut down Sora, their video generation tool, because the compute costs of running it at scale were unsustainable. They even said they were reallocating Sora’s servers to higher-priority workloads. Think about that. That’s a company admitting it doesn’t have enough infrastructure to run everything it wants to run. The supply constraint isn’t theoretical. It’s in their own blog post.
When you see that, it’s hard not to conclude these are growth-phase prices. The same playbook Uber used with rides, DoorDash used with delivery, and every SaaS company uses during growth mode. Get users hooked at an artificially low price, then raise prices once switching costs are high enough. Each time a product like Sora gets pulled, it tells you the true cost of running these models isn’t what’s on the tin.
Now, Uber held prices artificially low for the better part of a decade. Could AI companies do the same? Maybe. But there’s a key difference. Uber’s subsidy only required cash. The infrastructure already existed: roads, cars, drivers. You can fund below-cost rides with venture money as long as investors keep writing checks. AI companies are trying to subsidize prices while simultaneously building the infrastructure to deliver the product. That’s a much more expensive position to hold, and the longer demand keeps growing, the harder it gets to maintain.
At some point, token prices will have to reflect actual costs. And actual costs, as we’ve established, will be pushed upward by infrastructure constraints.
The people projecting that AI will be “10x cheaper next year” are extrapolating from prices that were never real to begin with.
Efficiency gains won’t outrun demand#
OK, here’s the thing. Inference efficiency HAS improved dramatically. Model distillation, quantization, better architectures, new silicon like the RISC-V AI chips that promise to make everything 10x cheaper. Some of that will deliver real gains. And I keep seeing people point to those gains as proof that costs will keep dropping forever.
I’ve watched this exact movie before. I know how it ends.
Remember when companies started moving to cloud infrastructure? The pitch was compelling: compute and storage costs are dropping, so moving to the cloud will save you money. And per-unit costs did drop. The price of a virtual machine or a gigabyte of storage fell steadily.
But here’s what actually happened. Because compute was cheaper, companies used dramatically more of it. Workloads that weren’t economical before suddenly were. Teams spun up environments they never would have provisioned in an on-prem world. I’ve been in the room for these conversations at multiple companies. The per-unit cost goes down, everyone celebrates, and then the annual cloud bill comes in 40% higher than last year because consumption exploded.
Today, most companies are spending more on their P&L for cloud costs than they ever spent on data centers. The per-unit savings were real, but consumption grew faster. Every single time.
Economists call this Jevons Paradox: when you make a resource more efficient to use, total consumption often increases rather than decreases. It happened with coal in the 19th century, fuel efficiency in cars, cloud computing, and it’s happening right now with AI.
Every efficiency gain in AI makes new use cases economical. Cheaper tokens mean companies run AI on tasks they wouldn’t have considered a year ago. That drives total demand up. And when total demand grows faster than efficiency improves, the infrastructure constraints don’t ease. They intensify. A 10x efficiency gain doesn’t help if demand grows 100x.
The efficiency gains are real. They just have to outrun the demand they create, which is not a trivial task.
The math companies will have to do#
So what happens when infrastructure constraints push AI costs up while human labor costs stay relatively flat?
Companies start doing arithmetic.
A senior engineer costs roughly $250,000 to $350,000 fully loaded (salary, benefits, taxes, equipment, management overhead). That’s about $120 to $170 per hour of productive work. Right now, AI can do certain tasks at a fraction of that cost. The gap is wide enough that replacing human work with AI is a financial no-brainer for those tasks.
But that gap depends on token prices staying low. If infrastructure pressure doubles the delivered cost of AI, and demand keeps pushing it higher, the math starts to shift. Not for everything at once, but task by task, role by role.
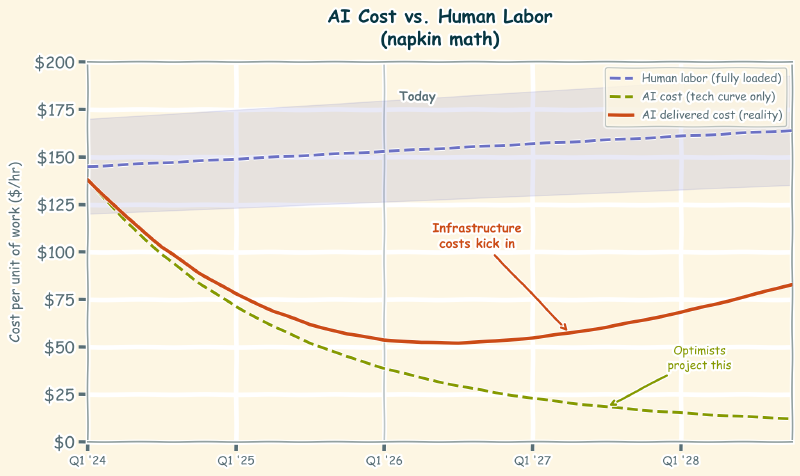
I’ve already been in this room. A team wants to use AI for a workflow, someone runs the numbers on token volume at scale, and the room gets quiet. The per-request cost looks trivial. The monthly cost at production volume doesn’t. Right now those conversations end with “the prices will come down.” Within a year or two, some of those conversations will end with “let’s just hire someone.”
We’re not at that inflection point broadly yet. For many tasks, AI is still dramatically cheaper. But at the pace adoption is accelerating, and with infrastructure struggling to keep up, we may see token costs plateau or rise sooner than anyone’s projecting.
When that happens, AI stops being a blanket replacement and becomes a cost-benefit decision made task by task. Some work will still be cheaper with AI. Some will be cheaper with people. Most will end up as a blend. And that blend looks a lot less like “your job disappears overnight” and a lot more like “your job changes gradually.” The difference matters. Gradual change gives you time to adapt.
Edge AI doesn’t solve this either#
Apple Intelligence, local LLMs, on-device inference. If AI moves to the edge, doesn’t that route around the data center bottleneck entirely?
Partially. But anyone who’s shipped software across device fragmentation is already wincing. Moving AI to the edge doesn’t simplify the problem. It fragments it. Now instead of one 400-billion-parameter model running in a controlled data center environment, you have a 3-billion-parameter model running on seventeen different phone chipsets, four tablet variants, and a laptop that’s two OS versions behind. Each one behaves slightly differently. Each one has different memory constraints, thermal limits, and failure modes.
That’s not fewer problems for humans to solve. That’s dramatically more, spread across more environments, with less margin for error. On-device models are less capable by definition, which means more careful prompt engineering, more fallback logic, more testing across hardware, and more human judgment about where the edge model is good enough and where you still need to call home to the data center.
The pitch is “AI moves closer to the user and everything gets simpler.” The reality is that distributing AI across millions of heterogeneous devices is one of the harder engineering problems you can take on. Anyone who’s shipped software across device fragmentation knows this in their bones. That’s the kind of problem that creates work, not eliminates it.
What this actually means for your career#
The pace at which AI replaces human work is governed by economics, not just capability. And the economics are about to get more complicated, not simpler. Infrastructure constraints, rising input costs, subsidized pricing that can’t last, and demand outpacing supply all put upward pressure on the cost of AI. That upward pressure is the natural brake that slows the “replace everyone” timeline.
Your career has more runway than the doomers suggest. Not infinite runway, but enough to adapt. Enough to learn how to work alongside these tools. Enough to position yourself as someone who makes AI more effective rather than someone AI makes redundant.
The people telling you to panic are either modeling the technology curve in isolation (which is a polite way of saying they’re wrong) or they have a financial interest in you believing the timeline is shorter than it is. The real world has data centers to build, power grids to expand, water to allocate, and supply chains to scale. All of that takes time. Human time, the kind that doesn’t compress no matter how smart the model gets.
At some point, all technology has to deal with the realities of human-scale problems. It’s naive to project timelines as if technology scales unimpacted by the physical world. The longest tail in any technology revolution isn’t the innovation curve. It’s the infrastructure curve.
And right now, that curve is working in your favor.